Map collection | What is an associative array data structure
An associative array, dictionary or map is a collection of key-value pairs. Learn about HashMap, LinkedHashMap, and TreeMap in Java — and how to use a HashMap to remove duplicates from a linked list.
An associative array, dictionary or map in computer science is a collection of data in the form of key-value pairs. In each collection, there is a unique key that is associated with a value.
The idea is that we can find a specific value directly by its unique key. This provides faster access times rather than the linear search based collections.
Different types of such data structures in Java, for example, include amongst others the HashTable, HashMap, TreeMap, LinkedHashMap and ConcurrentMap.
Check out the Java docs to find out more associative data structures like these.
In this post, I will be covering the three most popular map collections in Java. The HashMap, the LinkedHashMap and the TreeMap.
HashMap
A HashMap in Java is an implementation of the Map interface which works on a hashing principle.
This means we can insert an object by calling the put(key, value) method providing the key and the value. It then uses the hashcode() and equals() methods of the key object, to link the key to the value.
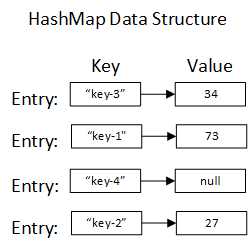
HashMap uses Map.Entry elements to store each object, which is a Java entry object that includes the key and the value we saved in the map. We then can call the get(key) method to access the particular entry and its value.
Additionally, the HashMap implementation provides a constant time performance assuming the elements are spread properly. Though, it does not keep the entries stored in the collection in a sorted order.
HashMap Vs HashTable
One more thing we need to know about a HashMap is that it is not a synchronized data structure and also not a thread safe one. This means we cannot share it between multiple threads without properly synchronizing it.
And that is one of the very few differences between a HashMap and a HashTable. A HashTable is a synchronized and thread-safe data structure, and we can share it amongst multiple threads.
Additionally, a HashTable does not allow any null key or value, whereas a HashMap allows one null key and multiple null values.
The HashMap is actually the advanced and improved version of the HashTable and is preferred as long as we do not care about thread synchronizations.
LinkedHashMap
This data structure extends the HashMap class and therefore inherits all its methods as well as logic.
A LinkedHashMap differs in the way it links entry objects in between them. As we have seen earlier, a HashMap does not save its entries in a sorted order. LinkedHashMap on the other hand, and as clearly stated by its name, keeps an linked list implementation of all its entries.
Meaning that each entry object in the map keeps a reference to its next and previous entries in the list. In this way, the map maintains the insertion order. The LinkedHashMap keeps a reference to the head of that linked list of entries.
This implementation, and as with the HashMap, provides a constant time performance.
TreeMap
As with the previously mentioned data structure, a TreeMap stores data with the same key-value pair elements.
The difference between a HashMap and a TreeMap is that a TreeMap stores its entry elements in an ascending sort order while implementing the SortedMap instead of the Map interface.
According to the Java docs, a TreeMap sorts its entries based on a natural ordering of their keys or on a custom Comparator you may provide at the time of the map creation.
TreeMap key sorts its entries on a Red-Black tree algorithm basis (a Self Balancing Binary Search Tree, which I will go through on another post), which provides a guaranteed log(n) time cost for the containsKey, put and remove operations.
Conclusions
As mentioned in the beginning there are different types of these data collections for different kind of usages and scenarios.
A HashMap collection is a commonly used data structure and a very cool one, providing us with an easy yet creative key-value pair data structure; that we may use to solve different problems while being cost-effective in terms of time or even space complexities.
Finally, I share below an example (amongst others you may find out there) of how I used a HashMap collection in Java to remove duplicates from a custom linked list.
I hope you liked this post and stay tuned for more!
Remove Duplicates from a Linked List with a HashMap
On this simple usage of the HashMap data structure, I'm elevating the unique key of the entry object in order to find duplicates in a linked list.
// Node class
static class Node {
int data;
Node next;
public Node(int data){
this.data = data;
this.next = null;
}
}
static Node removeDuplicates(Node head){
// null check here
if(head == null || head.next == null) return head;
// create a temporary node
Node next = head;
// create HashMap array
HashMap<Integer, Integer> map = new HashMap<>();
// insert node in map
map.put(next.data, 1);
// iterate list and insert rest of nodes in map
while(next.next != null){
// check if node already exists in map
if(!map.containsKey(next.next.data)){
map.put(next.next.data, 1);
next = next.next;
} else {
next.next = next.next.next;
}
}
// return the head of list
return head;
}
PS. Always remember to be creative with how you use all those awesome tools.