Trees | Non-Linear Data Structure Part One: Binary Tree & BST
A deep dive into tree data structures — nodes, edges, height, depth, Binary Trees, and Binary Search Trees with Java implementations for add, find, delete, and DFS/BFS traversals.
While going through the various data structures in a previous post, I briefly touched on what a tree data structure is, on which I wanted to dedicate a separate post for.
This is not as easy as array data structures (not that difficult to understand though), so bear with me through this series of posts.
What is a Tree structure
A tree data structure, along with graphs, are two non-linear data structure that store data in a non-common but specific way (compared to linear structures collections such as arrays).
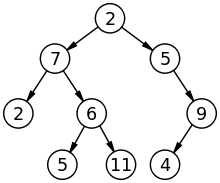
Technical definition
Trees are a collection of data formed of data elements called Nodes; Nodes are connected to each other by edges; each node element may or may not have child nodes.
In each Tree collection, we have one root node, which is the very first node in our tree.
If a node is connected to another node element, it then becomes a parent node and its connected node is its child node.
The link between the two connected nodes is called an edge. Edges are very important, as they define the relationship between nodes.
On a tree, the very last nodes are called leaves. Leaves are child nodes that do not have any children of their own, instead, they point to Null.
In trees, we use some very important concepts of measurement such as a node's height and depth.
To measure the height of a node, we simply find the longest path downwards from that node to a leaf and count the number of nodes in that path (excluding the current node).
For example, the height of a tree is the number of nodes in the longest path from the root to a leaf in the tree, excluding the root; the height of a leaf is 0.
To measure the depth of a node, we count the number of nodes in the path from that node upwards to the root of the tree (excluding again the current node). For example, the depth of the root in a tree is 0.
We might also hear the terminology of degree, which is for a given node the number of its children. For example, a leaf is of zero degrees.
Types of Trees
There are different categories of trees such as Binary trees, B-trees, Heaps, Tries, Multiway trees, Space-partitioning trees and Application-specific trees.
All of those tree categories, include multiple other sub-types of trees, which you may find a list here.
In this posts series, I'm not going to go through all of them, just the most commonly used ones.
These include the Binary Tree, Binary Search Tree, AVL Tree, Red-Black Tree, Splay Tree, Heap and Tries. So, let’s get started.
Binary Tree
A Binary Tree, which is the most basic form of a tree structure, is a data structure where each node has at most two children. Those two children are referred to as the left and right children.
Let’s have a look at the code behind a basic binary tree node.
class Node{
int data;
Node left;
Node right;
public Node(int data){
this.data = data;
this.left = null;
this.right = null;
}
}
In the above code, we can see a Java class called Node; the node class keeps a reference to one int data type value as well as two other Node class objects, its children.
Additionally, something I forgot to mention and is worth mentioning here is that we have different types of binary trees.
Full Binary Tree
We have a full binary tree when every node of the tree has two or zero children.
Complete Binary Tree
A complete binary tree is formed when every level of the tree is completely filled, except possibly from the last one. Also, the last level has all nodes as left as possible.
Perfect Binary Tree
We get a perfect binary tree when all tree internal nodes have two children, as well as all leaves, are uniformed by having the same depth.
Balanced Binary Tree
A balanced binary tree is formed when the tree's height is O(Log n), with n being the number of nodes. We will explain this later on with AVL and Red-Black trees which are the most commonly used balanced binary search trees.
Binary Search Tree
A binary search tree uses a binary tree at its basis with certain properties making sure that every left child in the tree has a smaller value than its parent value and every right child has a greater value.
Let’s have a look at the code of the method that created a BST, the add new node method.
Add Node
public class BinarySearchTree {
// BST Root Node
private Node root;
// Add new node to the BST
public void add(int val){
this.root = add(root, val);
}
// Add new node to the BST recursive helper method
private Node add(Node root, int val){
// null check
if(root == null) return new Node(val);
if(val < root.data){
// add left child
root.left = add(root.left, val);
}else if(val > root.data){
// add right child
root.right = add(root.right, val);
}
return root;
}
In the above code snippet, we have a Java class called BinarySearchTree that keeps a reference to a root Node class object, which is actually the root node of our BST.
Following our code, we have the add node method. This method checks the value we want to add to the BST. If the root node is empty, we then create a new root node with the requested value.
Otherwise, if the value exists in the BST, we just end the method there and do nothing to the root node.
If the value is smaller than the root's value, we get the left child of the node and pass it to the add method along with that value. We do the same with the right child of the node if the value is greater.
The private add method we used to add the right or left children of the node is used in a recursive way. Meaning that we will repeat all of the above-mentioned steps again until we find the appropriate slot in the tree for our new node value.
And that is how we create a BST with the add node method.
Find Node
Another important feature BSTs implement is the search tree or find node method, which will traverse the BST and find elements in it. Let’s have a look at the code.
// Find a node in the BST
static Node find(int val){
return find(root, val);
}
// Find a node in the BST recursive helper method
private static Node find(Node current, int val){
// return Null if BST does not contain given node
if(current == null) return null;
// return current node if matches given node
if(current.data == val) return current;
// traverse the remain BST via node children
return current.data > val ? find(current.left, val) : find(current.right, val);
}
In the above code, I am checking each node's data against the given value.
If the values are the same I then return the current node.
If the current node's value is greater than the given value, I perform the same check by recursively calling the find method on the left child of the current node.
I do the same on the right child if the node's value is greater than the given value.
Delete Node
Another very important method of the BST is the delete node method. This is a very special feature because, while we traverse the BST using the find method, we then need to delete that node and reorganize our BST.
Let’s have a look at how we can do this in code.
// Delete a node in the BST
static void delete(int val){
delete(root, val);
}
// Delete a node in the BST recursive helper method
private static Node delete(Node current, int val){
// could not find node in BST
if(current == null) return null;
// Found node, lets delete it
if(val == current.data){
// if node has no children simply delete it
if(current.left == null && current.right == null) return null;
// if node has only one child, remove that node and connect
// its child directly to parent
if(current.left == null) return current.right;
if(current.right == null) return current.left;
// if node has two children we need to reorganise them
// find the smallest node on the right subtree
int smallestValue = findSmallestNode(current.right);
// replace it with the current node
current.data = smallestValue;
// then delete it from the right subtree
current.right = delete(current.right, smallestValue);
// end method
return current;
}
// check on the left side of the BST
if(val < current.data){
current.left = delete(current.left, val);
return current;
}
// check on the right side of the BST
current.right = delete(current.right, val);
return current;
}
// helper method to find smallest node on a Tree
private static int findSmallestNode(Node current){
return current.left == null ? current.data : findSmallestNode(current);
}
So in the above code, we are searching the BST for a given node that we want to delete. When we find the given node in the tree, we then check against three different possibilities.
- In the case that the node does not have any children, we just return Null and remove that node from the BST.
- In the case that the node has just one child, we just connect its parent directly to its child; causing the tree to skip that node and hence removing it.
- In the case that the node has two children, what we do is a check to find the smallest node in its right subtree. We then replace the smallest node with the node we want to delete. And finally, we find and remove that smallest node from the right subtree.
Traversal
A BST can be traversed in different ways, such as the depth-first and breadth-first searches (DFS & BFS).
Depth-First Search
With the Depth-First Search approach, we traverse the tree by going as deep as possible in every child of the tree before jumping on to the next sibling node.
Additionally, we have different ways of DFS, such as the In-Order, Pre-Order and Post-Order traversals, on which I'm sharing some code below on how each works.
In-order
In-order traversal will first go through all of the left sub-tree, after that the root node, and lastly the right sub-tree.
// DFS in-order print of all values of BST
static void printInOrder(Node current){
// print left child
if(current.left != null) printInOrder(current.left);
// print current node data
System.out.println(current.data);
// print right child
if(current.right != null) printInOrder(current.right);
}
Pre-Order
Pre-order traversal will first go through the root node, then the left sub-tree, and finally the right sub-tree.
// DSF pre-order print of all values in BST
static void printPreOrder(Node current){
// print current node data
System.out.println(current.data);
// print left child
if(current.left != null) printInOrder(current.left);
// print right child
if(current.right != null) printInOrder(current.right);
}
Post-Order
Post-order traversal will first go through the left sub-tree, then the right sub-tree, and last the root node.
// DFS post-order print of all values in BST
static void printPostOrder(Node current){
// print left child
if(current.left != null) printInOrder(current.left);
// print right child
if(current.right != null) printInOrder(current.right);
// print current node data
System.out.println(current.data);
}
Breadth-First Search
In a Breadth-First Search (BFS) traversal approach, we go through all nodes of the same level before proceeding to the next level.
Such type of traversal is also called level-order and traverses the tree by going through all nodes of each level starting from the root node and in a left to right node direction.
I've already mentioned an example of BFS implementation, and with code example, while writing a post on queues here.
To be continued…
Covering the Binary Tree and Binary Search Tree, I'm ending the part one of this series of commonly used tree data structures.
I hope you enjoyed this post! Stay tuned for part two and more!
Friendly reminder, these blog posts are a series of my notes and thoughts, of which I’m trying to organize whilst sharing them with you guys here. So any feedback or suggestions are more than welcome! You may reach out to me in different various ways mentioned in the footer.